DeepSeek V4-Pro: Злетівши на вершину, відкриває нову еру ШІ-моделей
“`ukrainian

DeepSeek Революціонізує ШІ: Флагманська Модель V4-Pro Перевершує Конкурентів
Китайський стартап у сфері штучного інтелекту DeepSeek представив анонс своєї нової лінійки мовних моделей, що вже викликало значний резонанс. Зокрема, флагманська версія V4-Pro продемонструвала результати, що перевершують відомі Claude Opus 4.6 та GPT-5.4, закріпивши за собою статус найкращої відкритої системи на ринку.
Деталі Новітніх Розробок
Модель V4-Pro вражає масштабами: вона налічує близько 1,6 трильйона параметрів, проте під час виконання завдань активно використовує лише 49 мільярдів. Молодша версія, V4-Flash, має загальний обсяг 284 мільярди параметрів, з яких активується 13 мільярдів.
Обидві моделі базуються на передовій архітектурі “суміші експертів” (Mixture of Experts, MoE). Ця технологія дозволяє задіювати лише ті підмережі, які безпосередньо відповідають за обробку поточного токена, що робить процес більш економічним порівняно з суцільними архітектурами, зберігаючи при цьому високу продуктивність.
Процес попереднього навчання був надзвичайно масштабним: він охопив понад 32 трильйони токенів. Надалі розробники undertook поетапне донавчання, створюючи спеціалізовані модулі для роботи з кодом, математичними задачами, логічними висновками та виконанням інструкцій. Фінальна версія об’єднує ці навички за допомогою методу дистиляції.
Прорив у Обробці Довгих Послідовностей
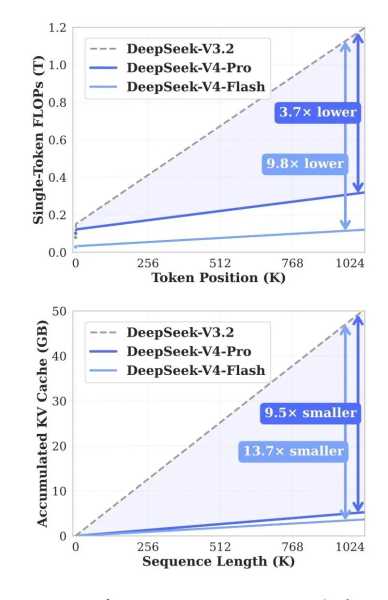
Однією з ключових переваг V4 стала суттєва оптимізація роботи з довгими послідовностями тексту. Хоча контекстне вікно розміром 1 мільйон токенів вже існує в інших моделях, його використання часто пов’язане зі значними витратами та затримками.
DeepSeek стверджує, що їхня нова версія суттєво зменшує навантаження при таких операціях. Порівняно з попередньою версією V3.2, V4-Pro потребує приблизно на 27% менше обчислювальних ресурсів та на 10% менше пам’яті KV-кешу при роботі з максимальним контекстом. Для V4-Flash ці показники складають близько 10% та 7% відповідно.
Джерело: Hugging Face.
Таких результатів вдалося досягти завдяки гібридній архітектурі уваги, яка включає два механізми для стиснення даних та зниження навантаження при обробці великих обсягів тексту. Додатково були впроваджені спеціальні гіперзв’язки для забезпечення стабільності та оптимізатор Muon для прискорення процесу навчання.
Гнучкі Режими Роботи V4
DeepSeek V4 пропонує три режими для роботи з інформацією:
- Non-think: для швидких відповідей на прості запитання без додаткового аналізу.
- Think High: для глибокого аналізу складних завдань та планування.
- Think Max: максимальний режим, в якому модель детально прописує кожен крок та перевіряє всі можливі варіанти.
У завданнях, що вимагають роботи агентів, режим Max тепер здатен зберігати ланцюжок проміжних кроків в межах одного завдання. Раніше частина такого контексту могла втрачатися під час взаємодії з користувачем.
Порівняльні Результати та Оцінки
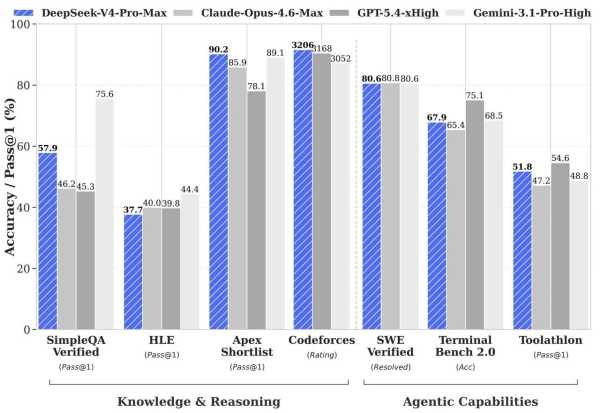
Згідно з даними DeepSeek, флагманська версія демонструє результати, які можна порівняти з провідними системами у багатьох сферах:
- У сфері програмування на платформі Codeforces модель досягла рейтингу 3206, що відповідає 23-му місцю серед найкращих програмістів світу, демонструючи паритет з GPT-5.4.
- У математичних завданнях результати склали 95,2 на HMMT 2026 та 89,8 на IMOAnswerBench, що дозволило випередити більшість конкурентів.
- У тестах на знання SimpleQA Verified модель показала 57,9 (Opus 4.6 – 46,2, але Gemini 3.1 Pro – 75,6).
- У сфері логічних міркувань моделі відстають від GPT-5.4 та Gemini 3.1 Pro лише на три-шість місяців.
- У внутрішньому тестуванні DeepSeek, яке включало завдання з розробки, налагодження та рефакторингу коду, модель отримала 67% – результат знаходиться між Sonnet 4.5 (47%) та Opus 4.5 (70%).
- В агентних сценаріях та завданнях розробки V4-Pro-Max продемонструвала 80,6% на SWE Verified та 67,9% на Terminal Bench.
Джерело: Hugging Face.
Розробка V4 була спеціально спрямована на реальні сценарії використання, зокрема: аналіз даних, створення звітів, редагування документів, а також пошук інформації в інтернеті з ітеративним застосуванням інструментів.
Для оцінки придатності моделі до реальної розробки, стартап провів внутрішнє тестування на завданнях, типових для його інженерів. Згідно з опитуванням 85 розробників та дослідників, 52% заявили про готовність використовувати V4-Pro як основну модель для програмування, а ще 39% висловили схильність до такого рішення.
Нагадаємо, 23 квітня компанія OpenAI представила GPT-5.5, яку позиціонує як “новий рівень інтелекту для реальної роботи та управління агентами”.
Порада від Business News:
Нові розробки від DeepSeek, зокрема модель V4-Pro, є значним кроком вперед у сфері відкритих мовних моделей. Вони пропонують не лише високу продуктивність, порівнянну з комерційними гігантами, але й покращену ефективність, особливо при роботі з великими обсягами даних. Це може стати цінним інструментом для розробників, дослідників та компаній, які шукають потужні, але при цьому доступні рішення для своїх проектів.
“`
Джерело новини: cryptocurrency.tech